前言使用本教程请严格遵守中华人民共和国法律Troubleshooting any problem without the error log is like driving with your eyes closed.在没有错误日志的情况下解决任何问题无异于闭眼开车。--Apache HTTP Server Documentation Getting Started2024/01/06更新 适配2.3版本本文的编写的过程中假定了一些前提:1. 您拥有较高的连通性的网络,可以正常访问PIP源 Gi
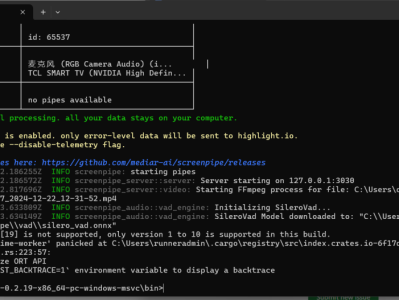
简介比如我今天开了一个网站,但是我忘记网址了,这样ai能记得,ai就能帮我找回来,或者一个打开过海报PNG,我忘记在哪了,ai也能帮我开打。最后也就是ai可以帮你省心的做一个日报,到点下班ai帮你做日报,不用加班了。老板们可以用它监控员工的操作,找到员工摸鱼证据视频教学https://www.bilibili.com/video/BV1Gjwne6Ejc/操作1、安装 Screenpipe(实时记录屏幕、声音)安装仅需一行代码### macos, linux 系统:
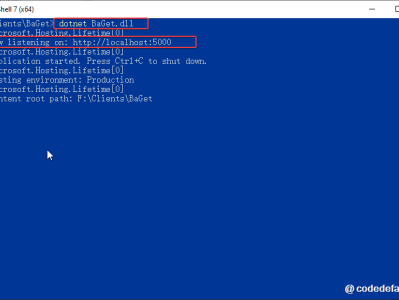
NuGet是什么?为什么.NET项目中会有NuGet?如何使用NuGet程序包?我们了解了:NuGet是什么?为什么.NET项目中会有NuGet?如何使用NuGet程序包?特别的,文中学习了如何安装基于微软官方托管(nuget.org)的共享NuGet包。那现在有人可能会问了:“我的程序集是个人或公司内部的,如果以都发布到nuget.org托管,那么不是所有都能下载和引用了吗?有没有可能把个人或公司内部的程序集上传到一个私有的NuGet服务器,只让部分开发者可以访问呢?”答案是肯定的,你想到的别
在.NET应用程序编程开发中,开发者通常使用类库来管理、维护属于同一分类的程序代码,以便代码的重用。一般情况下,处于同一类库的所有类都位于同一程序集。这些类库被编译器编译后会生成扩展名为.dll的动态链接库文件,你可以在其它项目中通过引用的方式导入这些.dll程序集并使用其中被封装的类及成员。但随着项目越来越大、越来越多,使用手动引用.dll动态链接库的方式让程序包管理和维护变得非常困难。在这种情况下,NuGet程序包管理工具便应运而生。NuGet程序包就好比前端开发中的npm包,Java开发中
DeepSeek从春节一直火到现在,我除了看各种报道资料向大家学习之外,也一直考虑着能拿手头什么样的硬件配置玩一下:)今天我要分享的结论很简单。当然除了下表之外,还想补充点经验给大家参考——包括我自己的,也包括来自同行友人的。测试模型DeepSeek-R1-UD-IQ1_S(671B,Dynamic 1.58-bit)OSUbuntu 24.01 LTSCPUAMD EPYC 8534P(64核,SP6,Zen4c)内存6通道192GB DDR5-48004通道256GBToken/s
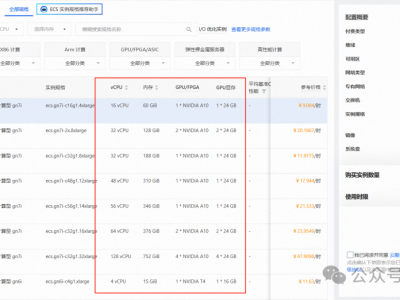
目录环境准备配置步骤一、配置 GPU 云服务器二、安装 conda三、显卡驱动安装四、vllm 安装五、大模型下载与运行客户端调用测试环境准备1. anaconda2. python 环境3. VLLM(注:只可运行在Linux系统中)4. 云服务器或本地物理服务器;(本文以云服务器部署为例)配置步骤一、配置 GPU 云服务器1.购买云服务器 GPU 计算型根据实际需要选择等待实例初始化2.在本地电脑使用 ssh 连接服务器这里我使用私钥进行连接二、安装
Cherry Studio:开源AI客户端,使用DeepSeek提升效率神器介绍一下Cherry Studio的相关使用。Cherry Studio的介绍Cherry Studio是一个开源的支持多模型服务的桌面AI客户端,为专业用户而打造。集成了超过 300 多个大语言模型,内置 30 多个行业的智能助手,帮助用户在多种场景下提升工作效率。支持macOS、Windows、Linux。提供了丰富的功能,如:对话、智能体、绘画、翻译、知识库等功能在Cherry Studio中使用硅基流动Cherr
开源!基于DeepSeek的本地化企业内部知识库和工作流平台, 允许商业化源代码http://www.gitpp.com/sciences/deepseek-localweb-ragDeepSeek本地知识管理平台:全面、安全、高效的智能解决方案在当前数字化和信息化的浪潮中,企业和机构对于高效、安全的知识管理和智能服务需求日益增长。DeepSeek本地知识管理平台应运而生,它基于DeepSeek这一开源且性能卓越的大模型,旨在为企业和机构提供一套功能全面、安全高效的智能解决方案。一、文档智能功能
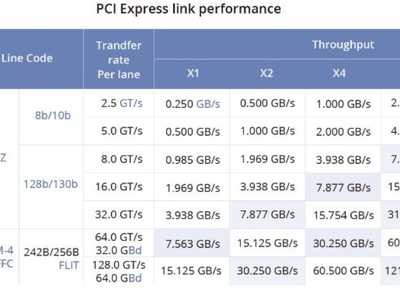
0x01 传统Pcie与NVLink1. PCIe(Peripheral Component Interconnect Express):它是一种计算机总线标准,用于在计算机内部连接各种设备和组件(例如显卡、存储设备、扩展卡等)。PCIe接口以串行方式传输数据,具有较高的通信带宽,适用于连接各种设备。然而,由于其基于总线结构,同时连接多个设备时可能会受到带宽的限制。2. NVLink(Nvidia Link):它是由NVIDIA开发的一种高速、低延迟的专有连接技术,主要用于连接NVIDIA图形处
在人工智能和大型语言模型(LLMs)领域,Ollama作为一款专注于简化大型语言模型在本地部署和运行的开源框架,受到了广泛关注。然而,Ollama并非唯一的选择,市场上还有许多其他同类型的工具,为开发者提供了多样化的选项。本文将盘点与Ollama同类型的大模型框架工具,帮助用户更好地了解这一领域的技术生态。一、Ollama框架简介Ollama是一个专注于简化大型语言模型(LLM)在本地部署和运行的开源框架。它支持多种大型语言模型,如Llama 2、Code Llama、Mistral、Gemma
Ollma和vLLM简单对比AI应用开发中最常见两个大模型推理框架Ollama和vLLM. 在应用开发过程中,开发者通常会从多方面进行比较来选定适合的推理框架,尤其是在对接本地大模型时,考虑因素包括本地资源配置,本地安全性要求,成本计算,响应要求等多个方面。下面针对这两个常见框架,做一个简要的对比:Ollama1. 说明:Ollama是一个开源的大模型服务工具,可以让你在不写代码的情况下,在本地通过命令运行需要的大模型。Ollama会根据用户的资源配置,自动选择GPU或CPU运行,运行速度取决于
这两年是大模型盛行的黄金时代,各大优秀的大模型诸如GPT、LLM、QWen、Deepseek等层出不穷,不断刷新我们的认知;但是大模型都有一个共同的特点,都拥有非常惊人的参数量,小的都有上十亿的参数,大的更是可以有几千亿的参数,这么大的参数量就会带来一个新的问题,就是推理效率不如传统的深度学习模型,再有就是目前的大模型基本上都是基于transformer进行开发的,最大限制上下文token数会导致模型在显存的利用率上会有很大的缺陷,基于此,专
vLLM 专为高效部署大规模语言模型设计,尤其适合高并发推理场景,关于对vLLM的介绍请看这篇博文。以下从 安装配置、基础推理、高级功能、服务化部署 到 多模态扩展 逐步讲解。 1. 环境安装与配置1.1 硬件要求GPU: 支持 CUDA 11.8 及以上(推荐 NVIDIA A100/H100,RTX 4090 等消费级卡需注意显存限制)显存: 至少 20GB(运行 7B 模型),推荐 40