自建brook服务器教程 实现远程办公介绍:公司分了几个分公司(甚至跨国),这些分公司,如何访问总公司的内网资源呢? 这里,给大家推荐一款可用远程办公的工具,需要一些技术知识。2024年4月27日更新。自建brook教程很简单,整个教程分三步:第一步:购买VPS服务器第二步:一键部署VPS服务器第三步:一键加速VPS服务器 (五合一的TCP网络加速脚本)【前言】Brook是一款新兴的代理软件,其版本横垮Windows、安卓、iOS、MacOS、Linux等多个系统平台,功能
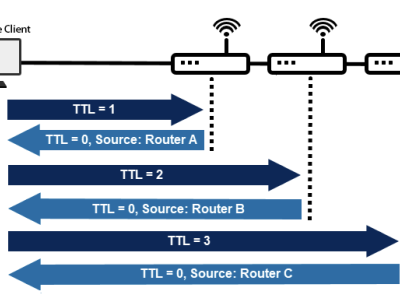
一、前言NextTrace为一款轻量化的开源可视化路由跟踪工具,目前支持ICMP、TCP、UDP等多种协议,并通过地址库显示每一跳节点的AS号、归属地情况,并通过路由可视化生成地图路径标注,光是这几样功能可谓对于网络故障定位起到非常大的作用,不排除后续会纳入到各个Linux发行版软件源中。截止到目前(2023.4),最新版本为v1.1.3,本文将从各个参数讲解NextTrace用法。二、细究探测原理探测原理很简单,通过TTL=1一直往上递增,每经过一跳,TTL减1,TTL耗尽后对端网关触发Tim
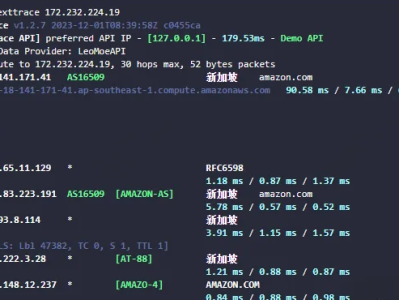
如果你日常会用到traceroute之类的工具,那么这个nexttrace项目下的工具一定要了解下。这是一款Golang 实现的开源的、轻量级的可视化路由追踪CLI工具,效果如下:项目简介NextTrace是一个go语言开发的路由追踪工具,相比于常规的工具,它可以将路由追踪到的信息展示为图像,可以更加具象化。如何安装功能特点IP库更加丰富,展示的I归属更加准确可以生成可视化追踪地图支持多种协议,icmp、tcp、udp支持多语言环境使用支持ipv6环境使用如何使用可以从如下开始,更多具体使用,可
什么?ESXi居然不支持4k扇区的硬盘?1.88TB的M2 PM983直接给ESXi装上。但是!ESXi居然看不到分区可以看到有两个NVMe SSD,但是点进去之后什么都没有。不过在硬件的地方,两个盘还是能看到的。这个什么情况?心里有一股不详的预感,难道帆船了么?卖家还是信得过的,买过好多次了。好吧,我只好拿出来FreeBSD14.的安装U盘,居然顺利就安装上了FreeBSD系统。盘应该是没问题。这到底是什么鬼?好吧,我们在FreeBSD来看一下这两个盘有什么不同。root@esxi:~&nbs
B站原视频:RGN-001 蜗牛星际NAS爆改!三千预算8T RAID1 十三分钟带飞OMV5和KVM_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com/video/av914088907:31开始视频教程安装cockpit + KVM软件包apt install cockpit cockpit-* qemu qemu-kvm qemu-utils libvirt-* bridge-
3分钟构建本地GPT,不用GPU,家用办公电脑便可构建安装 Ollama转到 Ollama 网站单击“下载”。选择与您的操作系统匹配的安装程序。按照安装向导进行操作。安装模型安装完 Ollama 后,你可以按照以下步骤来安装模型并运行:一、安装 Ollama 模型: 首先,确保你已经成功安装了 Ollama。如果你还没有安装,请参考之前的步骤。 打开终端或命令行界面。二、下载模型:Ollama 提供了一系列预构建的模型,你可以从 Ollama 模型库中选择一个。例如,你可以下
你好,今天聊一下 Self GPT。前几天 OpenAI 举办了自己的第一场开发者大会,当时就宣布了 ChatGPT 有一项重大的更新:每个人都可以创建一个自己 GPT,并且稍后还有一个 GPT Store 上线它。上一次乔帮主开放 App Store 的时候,开发者是使用 Objective-C 编程语言开发 iOS App,然后申请上架赚取佣金。这一次,OpenAI 把门槛降低了,不需要使用者会编程语言,甚至连清晰严格的提示(Prompt)也不需要编写了,操作很简单,用几句中文互动一下,就能
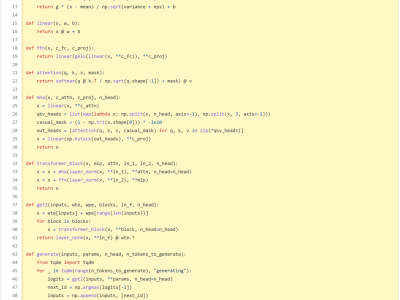
大型语言模型(LLM)被认为是人工智能突破的方向。人们正在尝试用它们做各种复杂的事情,比如问答、创作、数学推理以及编写代码等。近段时间 ChatGPT 持续的爆火是最好的例证。然而,对于机器学习从业者来说,大模型的门槛很高:因为体量太大难以训练,很长时间里这个方向一直被大公司垄断。不过最近,简化 GPT 模型的方法越来越多了。1 月中旬,前特斯拉 AI 高级总监 Andrej Karpathy(现已回归 OpenAI)就发布了从零开始构建 GPT 模型的完整教程。不过训练出的 GPT 和 Ope
RAG理论1. 什么是RAG众所周知,大模型基于海量的数据来训练,它具备非常强大的智能,能够回答各种问题。但是我们在使用过程中发现,通用大模型在某些专业领域能力还不够强,很多领域相关问题很难回答得上来。通常,预训练(pre-train)的大模型只懂得它训练时用的数据,对于训练集之外的新信息(比如网络搜索新数据或特定行业的知识)就不太清楚。那么怎么构建一个私有的GPT大模型呢?方法有很多种,包括 1. 重新训练私有领域数据的大模型,2. 基于已有大模型做专有数据的微调(FineTuning) 3.
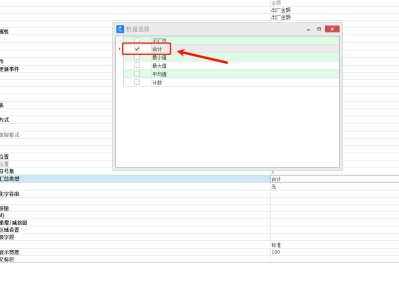
列表 数量或金额类型字段合计选择BOS中需要列表显示合计行的字段,修改“列表字段汇总类型”属性为“合计”,默认不汇总..效果:编辑页面,明细页签 数量或金额类型字段合计明细表单属性,分组列信息-->分组合计列 中,将需要合计的字段 选择到 右边 ..效果: